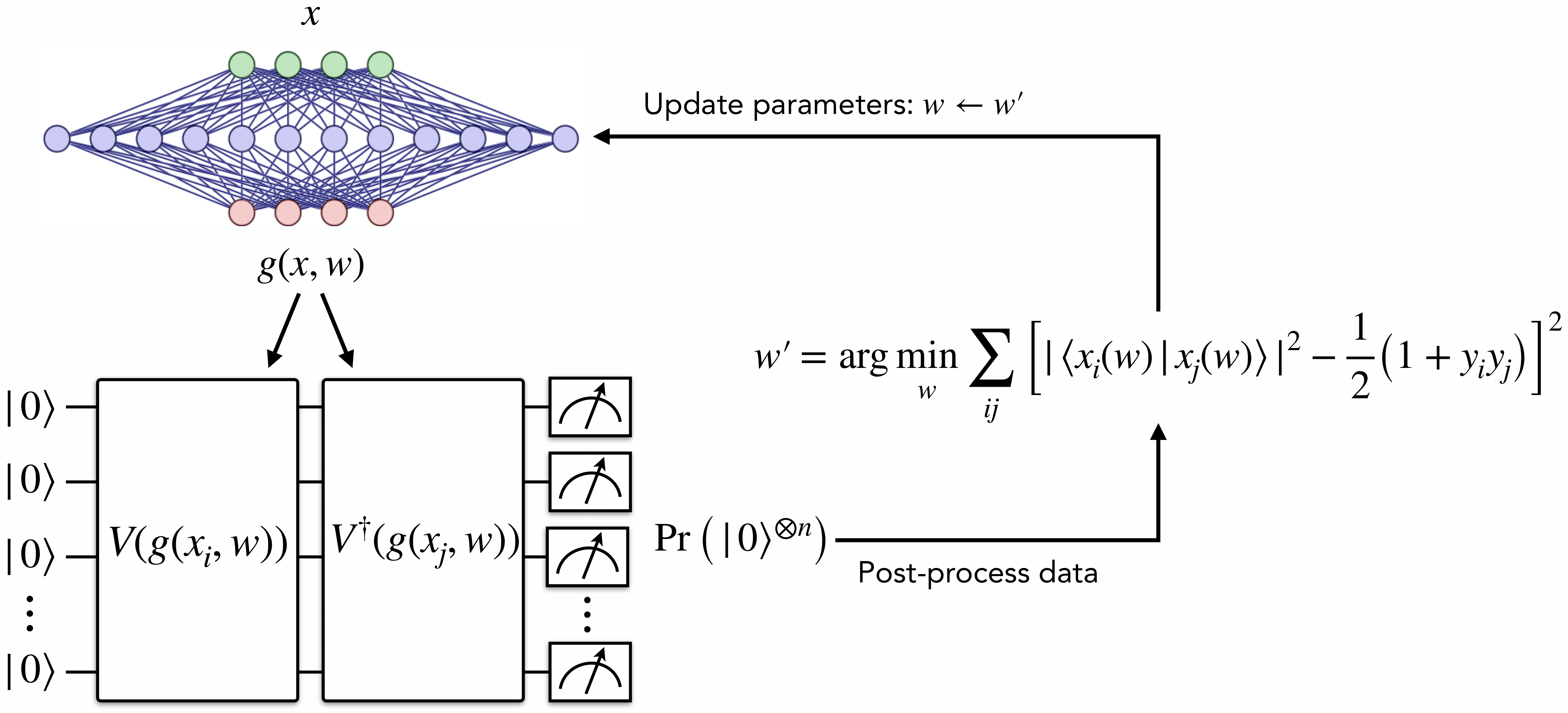
For quantum machine learning (QML) with classical data, we must initially map classical data into a quantum state. In this paper[1], we show the importance of quantum embedding and emphasizes the necessity of trainable data-dependent quantum embedding. We present Neural Quantum Embedding (NQE), which utilizes classical neural network to efficiently optimize quantum embeddign for given datasets. This is the introductory tutorial, the full code and experimental results can be found in this Github repository.
NQE utilizes trainable classical neural networks along with a quantum embedding circuit. The goal of NQE is find the optimal embedding that maximizes the trace distance between two data ensembles. Training the NQE with trace distance directly as a cost function is ideal, but calculating the trace distance is expensive even with the quantum computer. Here, we will use implicit loss function, inspired by fidelity overlap between two data class.
Alt text for the image
Although NQE scheme can be applied on general quantum embedding, we will focus on IQP type embedding introduced by Havlicek et al.[2]. This is a widely used quantum embedding scheme for QML due to its classical intractability. First, we define a IQP type quantum embedding.
For NQE, we construct a hybrid circuit by concatenating fully classical neural network with quantum embedding circuit. Then, we construct a quantum circuit that measures the fidleity overlap between two embedded quantum states.
Now we optimize the quantum embedding by training the classical neural network part of NQE. We will train for 200 iterations with batch size of 25.
Code
batch_size =25iterations =200#make new data for hybrid modeldef new_data(batch_size, X, Y): X1_new, X2_new, Y_new = [], [], []for i inrange(batch_size): n, m = np.random.randint(len(X)), np.random.randint(len(X)) X1_new.append(X[n]) X2_new.append(X[m])if Y[n] == Y[m]: Y_new.append(1)else: Y_new.append(0) X1_new, X2_new, Y_new = torch.tensor(X1_new).to(torch.float32), torch.tensor(X2_new).to(torch.float32), torch.tensor(Y_new).to(torch.float32)return X1_new, X2_new, Y_newmodel = Model_Fidelity()model.train()loss_fn = torch.nn.MSELoss()opt = torch.optim.SGD(model.parameters(), lr=0.01)for it inrange(iterations): X1_batch, X2_batch, Y_batch = new_data(batch_size, X_train, Y_train) pred = model(X1_batch, X2_batch) loss = loss_fn(pred, Y_batch) opt.zero_grad() loss.backward() opt.step()if it %50==0:print(f"Iterations: {it} Loss: {loss.item()}")torch.save(model.state_dict(), "model.pt")
/var/folders/s2/t3n82l2s329dh9dttmtv7vr00000gn/T/ipykernel_19536/422545311.py:16: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at /Users/runner/work/pytorch/pytorch/pytorch/torch/csrc/utils/tensor_new.cpp:257.)
X1_new, X2_new, Y_new = torch.tensor(X1_new).to(torch.float32), torch.tensor(X2_new).to(torch.float32), torch.tensor(Y_new).to(torch.float32)
/Users/tak/anaconda3/envs/new/lib/python3.10/site-packages/autograd/numpy/numpy_vjps.py:943: ComplexWarning: Casting complex values to real discards the imaginary part
onp.add.at(A, idx, x)
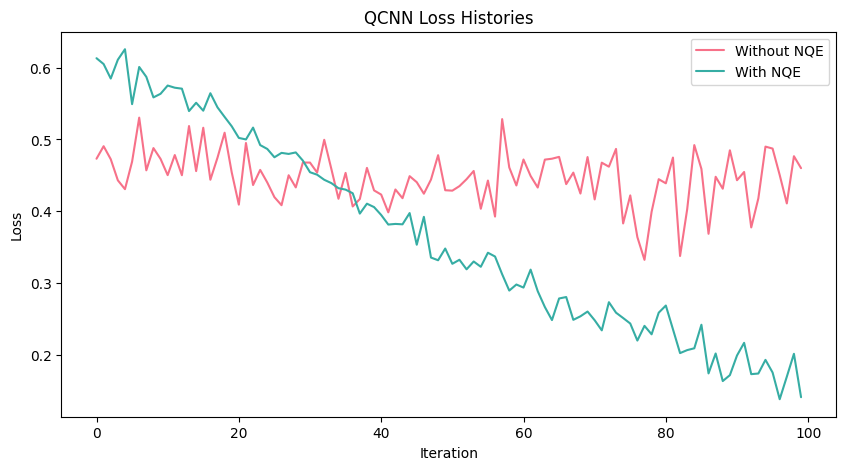
import seaborn as snsimport matplotlib.pyplot as pltplt.rcParams['figure.figsize'] = [10, 5]fig, ax = plt.subplots()clrs = sns.color_palette("husl", 2)with sns.axes_style("darkgrid"): ax.plot(range(len(loss_history_without_NQE)), loss_history_without_NQE, label="Without NQE", c=clrs[0]) ax.plot(range(len(loss_history_with_NQE)), loss_history_with_NQE, label="With NQE", c=clrs[1])ax.set_xlabel("Iteration")ax.set_ylabel("Loss")ax.set_title("QCNN Loss Histories")ax.legend()
We can see that the loss history is much lower when NQE is employed. Now let’s see how well QCNN can classify the MNIST image data.
Code
def accuracy_test(predictions, labels): acc =0for l, p inzip(labels, predictions):if np.abs(l - p) <1: acc = acc +1return acc /len(labels)accuracies_without_NQE, accuracies_with_NQE = [], []prediction_without_NQE = [QCNN_classifier(weight_without_NQE, x, NQE=False) for x in X_test]prediction_with_NQE = [QCNN_classifier(weight_with_NQE, x, NQE=True) for x in X_test]accuracy_without_NQE = accuracy_test(prediction_without_NQE, Y_test) *100accuracy_with_NQE = accuracy_test(prediction_with_NQE, Y_test) *100
Code
print(f"Accuracy without NQE: {accuracy_without_NQE:.3f}")print(f"Accuracy with NQE: {accuracy_with_NQE:.3f}")
Accuracy without NQE: 61.000
Accuracy with NQE: 98.000
Classification accuracy with NQE is significantly larger than the classification accuracy without NQE! If you want to how NQE affects training loss lower bound, trainability, generalization performance of QML models have a look at the original paper and the code!
References
Tak Hur, Israel F. Araujo, Daniel K. Park. Neural Quantum Embedding: Pushing the Limits of Quantum Supervised Learning. Physical Review A (2024).
Vojtech Havlicek, Antonio D. C ́orcoles, Kristan Temme, Aram W. Harrow, Abhinav Kandala, Jerry M. Chow, and Jay M. Gambetta. Supervised learning with quantum-enhanced feature spaces. Nature (2019).
Citation
If you use this code in research, please cite our paper:
@article{hur2024neural,
title={Neural quantum embedding: Pushing the limits of quantum supervised learning},
author={Hur, Tak and Araujo, Israel F and Park, Daniel K},
journal={Physical Review A},
volume={110},
number={2},
pages={022411},
year={2024},
publisher={APS}
}